Join에 대해서 알아보자
Posted 2008. 4. 11. 01:51Table2 : clients
Table3 : orders
1. The Cross Join
Cross Join은 가장 기본적인 join 타입으로 한 테이블에 있는 각각의 열이 다른 테이블의 모든 열에 간단하게 매치되어 출력된다. 능률적이지는 않지만, 모든 join의 공통된 특징을 나타내준다.
예 : select * from pcs, clients <== where절에서 조건이 없다.
즉 cross join은 테이블1에 있는 각각의 열들이 테이블2에 있는 모든열들을 한 번씩 교차해 출력한다고 기억하는 것으로 생각하면 된다.
아래의 쿼리는 어떻게 출력될 것인지 알아보자..
예 : select c.name, o.cid from orders o, clients c where c.cid = 'wjh-042';
result :
+--------+---------+
| name | cid |
+--------+---------+
| 원주희 | wjh-042 |
| 원주희 | wjh-042 |
| 원주희 | wjh-042 |
| 홍길동 | wjh-042 |
| 홍길동 | wjh-042 |
| 홍길동 | wjh-042 |
| 이쁘니 | wjh-042 |
| 이쁘니 | wjh-042 |
| 이쁘니 | wjh-042 |
| 못난이 | wjh-042 |
| 못난이 | wjh-042 |
| 못난이 | wjh-042 |
+--------+---------+
clients 테이블에 있는 각각의 name이 orders테이블의 'wjh-042'를 포함한 열마다 매치되어 출력되었다. 지금까지의 설명이 Cross Join을 설명하는데 충분하지 않으므로 다른 질의를 사용해가며 JOIN을 활용해보기 바란다.
NOTE: 왜 테이블의 이름에 별명(alias)을 주어 사용할까? Aliases는 질의를 입력할때 반복적인 키의 입력을 줄여주는 방법으로 사용된다. 따라서 열을 지정해 줄때 반복적으로 'clients'를 한자 한자 입력하는 대신에, 질의내에 'from clients c'를 지정해 주고 'c'를 사용할 수 있다.
2. Equi-join
Equi-join은 한 테이블에 있는 어떠한 값이 두번째(또는 다수의) 테이블내에 포함된 값에 일치 할 때 수행된다.
product id 가 1 인 pc를 주문한 고객의 목록을 원한다고 가정하면...
mysql > select p.os, c.name from order o, pcs p, clients c
where p.pid = c.pid and o.pid = 1 and o.cid = c.cid;
result :
+-------+--------+
| os | name |
+-------+--------+
| Linux | 원주희 |
+-------+--------+
3. Non-Equi-join
Equi-join은 다수의 테이블 사이에서 일치하는 자료들만을 추출해 낸다. 그러나 일치하지 않는 자료만을 추출해야 한다면? 예를 들어 당신의 상사가 주문한 pid가 제품의 pid보다 더 큰 order id의 모든 운영체제(OS)의 목록을 필요로 한다면 어떻게 할 것인가? 적당히 이름을 non-equi join 이라고 하겠다.
mysql> SELECT p.os, o.pid from orders o, pcs p where o.pid > p.pid;
result :
+-------+------+
| os | pid |
+-------+------+
| Linux | 2 |
| Linux | 3 |
| Linux | 2 |
| Linux | 5 |
| Linux | 5 |
| Linux | 3 |
| Linux | 5 |
| Linux | 5 |
| WinNT | 5 |
| WinNT | 5 |
| Linux | 5 |
| Linux | 5 |
+-------+------+
orders 테이블의 pid가 pcs테이블의 pid보다 더 큰 모든 열들이 매치될 것이다. 주의 깊게 살펴보면, 여러가지 제한을 준 간단한 cross-join임을 파악할 수 있을것이다. 상사에게는 특별하게 유용하지 않을 지도 모르지만, 매우 유용한 기능이 letf join을 위한 준비과정으로 생각하자,
4.Left Join
Left Join은 사용자가 어떠한 제한을 기반으로 관심있는 모든 종류의 자료를 추출하게 한다. 테이블 join중 가장 막강한 옵션으로, 테이블을 매우쉽게 조작할 수 있다.
mysql> select * from orders left join pcs on orders.pid = pcs.pid;
result :
+------------+------+---------+------+------+-------+------+------+
| order_date | pid | cid | pid | spec | os | ram | hd |
+------------+------+---------+------+------+-------+------+------+
| 1999-12-05 | 2 | wjh-042 | 2 | 386 | Linux | 128 | 4.2 |
| 1999-12-04 | 3 | hgd-043 | 3 | 486 | WinNT | 64 | 3.1 |
| 1999-12-04 | 1 | wjh-042 | 1 | 386 | Linux | 64 | 3.1 |
| 1999-12-05 | 2 | wjh-042 | 2 | 386 | Linux | 128 | 4.2 |
| 1999-12-12 | 5 | ugy-043 | 5 | 586 | Win98 | 128 | 6.4 |
| 1999-12-05 | 5 | pty-042 | 5 | 586 | Win98 | 128 | 6.4 |
+------------+------+---------+------+------+-------+------+------+
5. Using 절
left join에 약간의 옵션을 주어 둘 이상의 테이블에 있는 동일한 컬럼을 조금 더 깊게 연관지을 수도 있다. on과 using옵션이 사용되며 아래 예제 보자
mysql> SELECT * from clients left join orders on clients.cid = orders.cid;
mysql> SELECT * from clients left join orders using (cid);
위의 두 쿼리는 똑같은 결과가 출력될 것이다.
6.Self Joins
Self Join은 관리자가 하나의 테이블에 관련된 데이타를 집중시키는 막강한 방법을 제공.
self-join은 그 자신의 테이블에 결합하는 것에 의해 수행된다.
개념의 이해를 위해 예를 들어 설명하겟다.
mysql> select a.*, b.* from post a, post b where a.idx = b.ori_idx;
self-join은 테이블의 자료를 검증하는 방법으로도 사용된다. 테이블내에 있는 uniq_id는 유일해야 하며 만일 데이타의 엔트리가 깊어 뜻하지 않게 같은 uniq_id를 가지 ㄴ두개의 항목이 입력된다면 좋지 않을 결과가 생길것이다. 이럴 경우 정기적으로 self-join을 사용해 체크한다.
# Mysql Sub Query는 4.1부터 지원한다.
또다른 JOIN 관련 글.....
아래의 내용은 naver에서 "mysql join" 으로 검색된 결과이다.
주소는 http://cafe.naver.com/dbdiary/187 이것이지만 클릭하면 카페가입하라고 나온다.
반드시 검색창을 통해서 들어가야한다.
[TIP]
[JOIN과 속도 향상]
일반적으로 조인을 사용하면 루프 조인을 사용한다. 루프 조인은 한 테이블에 있는 값과 똑 같은 값을 다른 테이블에서 찾는 것을 반복한다.
따 라서 조인하는 적업은 대단히 비용이 많이 드는 작업이다. 보통 DBA가 개발자들이 만든 SQL 문중에서 조인이 많이 일어나는 테이블 컬럼에 인덱스를 걸어두는 것도 이 루프 조인이라는 것이 워낙 비용이 많이 드는 작업이기 때문이다.
조 인의 속도를 향상시켜주기 위해서는 일단 조인해야 하는 행의 개수를 제한해야 한다. 만약 A 테이블에 10개의 컬럼이 있고 B 테이블에 20개의 컬럼이 있다면 A 테이블의 한 개의 값에 대해 B 테이블 전체를 뒤져 A 테이블 한 개의 값을 찾는 것을 반복해야 한다.
그런데 A 테이블에서 10보다 큰 값 중에 B 테이블과 데이터가 같은 값을 찾는다면 상황이 틀려진다. A 테이블에서 10보다 큰 값이 2개만 있다면 2개의 행에 대해서만 B 테이블에서 검색하는 작업만하면 된다.
하지만 반대로 먼저 조인을 하고 난 다음에 10보다 큰 2개의 행을 걸러내는 것은 누가 보더라도 비효율적이다.
결 국 조인의 속도를 향상시키기 위해서 인덱스를 어떻게 잡느냐는 말할 것도 없이 중요하지만 인덱스 없이 테이블간의 조인을 한다고 가정하면 어떻게 조인할 행을 줄이느냐가 중요하다. 결과적으로 개발자들이 얼마만큼 데이터베이스를 이해하고 SQL 문을 만드는지가 데이터베이스 성능에 지대한 영향을 미친다.
물론, 요즘 데이터베이스에는 Optimizer가 있어서 알아서 가장 최선의 Query Path를 잡아준다. 하지만 자동이 항상 좋은 것은 아니다. 가끔 이 Optimizer가 제대로 작동하지 않을 때에는 Optimizer가 처리하는 방식이 더 느린 경우도 있다. 따라서 데이터베이스에 SQL 문을 입력할 때에는 항상 속도를 어떻게 높일 것인가에 대해서 고민할 필요가 있다.
===========================================================================================
그럼 먼저 두 테이블 관계를 만드는 SQL 문인 JOIN 문에 대해서 알아보도록 하자. JOIN문은 다음 표와 같이 다양한 조인의 방법이 있다. 이제 다양한 조인의 방법에 대해서 알아보도록 하자.
|
Table_reference INNER JOIN table_reference join_condition Table_reference [CROSS] JOIN table_reference Table_reference STRAIGHT_JOIN table_reference Table_reference LEFT [OUTER] JOIN table_reference join_condition Table_reference LEFT [OUTER] JOIN table_reference Table_reference NATURAL [LEFT [OUTER]] JOIN table_reference Table_reference RIGHT [OUTER] JOIN table_reference join_condition Table_reference RIGHT [OUTER] JOIN table_reference Table_reference NATURAL [RIGHT [OUTER]] JOIN table_reference |
[인너 조인[INNER JOIN]]
INNER JOIN은 두 테이블간에 동일한 데이터에 대해서 조인을 처리하는 것이다. 한 테이블에만 있는 데이터는 당연히 데이터베이스가 리턴하지 않는다.
현 재 주문 테이블과 고객 테이블은 1:1이다. 즉 고객 테이블에 있는 모든 고객이 주문을 한번은 했다는 이야기다. 만약 고객 등록만 하고 주문은 한번도 안한 고객이 있다면 INNER JOIN을 하게 되면 당연히 리턴되지 않는다. 다음 예를 통해서 이해해 보도록 하자.
우선 주문을 한번도 하지 않고 등록만 한 샘플 사용자를 넣어보자.

주문 테이블과 고객 테이블의 내용을 한번 더 확인한다. 고객 테이블에 'windowsh'이라는 아이디가 새로 추가되었고 주문 테이블을 보니 이 아이디는 한번도 주문을 하지 않았다.
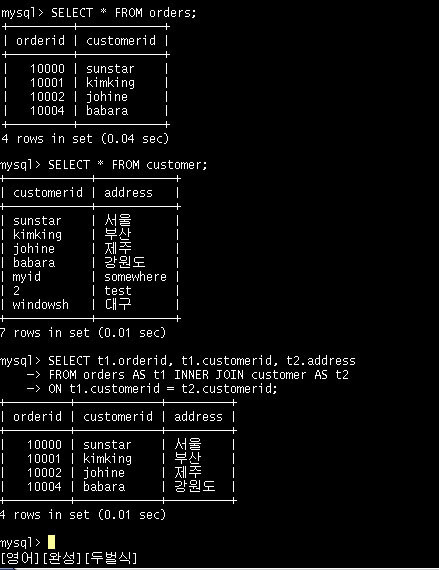
조인된 결과를 보면 'windowsh'이라는 고객이 주문을 한번도 하지 않았기 때문에 조인한 결과에서는 보이지 않는다. 위의 조인 문은 ANSI SQL 표준을 따른 예이다.
위와 같이 INNER JOIN 구문을 명시적으로 사용해도 되지만 일반적으로 WHERE 문 뒤에 조건과 똑 같은 방법으로 바로 써도 똑 같은 결과를 얻을 수 있다. 따라서 위 표준 SQL 문은 다음과 같이 바꾸어 사용할 수 있다.

[아우터 조인(OUTER JOIN)]
영어에서 INNER의 반대는 OUTER이다. 앞에서 INNER 조인이 두 테이블에서 공통된 데이터만을 가져온다고 설명했으니 OUTER 조인의 기능을 대충 짐작할 수 있을 것이다.
독 자 여러분이 추측한 대로 OUTER 조인은 두 테이블간에 공통된 데이터가 없다고 하더라도 모든 데이터를 가져오는 조인문이다. 또 OUTER 조인은 어떤 테이블을 기준으로 하느냐에 따라서 LEFT와 RIGHT 두 개의 조인으로 나눌 수 있다.
OUTER JOIN을 설명하는데 온라인 쇼핑 테이블이 적절하지 않기 때문에 샘플 테이블을 만들고 샘플 데이터를 채워보도록 하자.
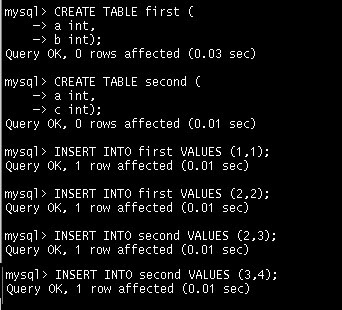
두 테이블에는 공통 컬럼으로 a 컬럼이 있다. First 테이블에는 1,2의 값이 있고 second 테이블에는 2,3의 값이 있다.
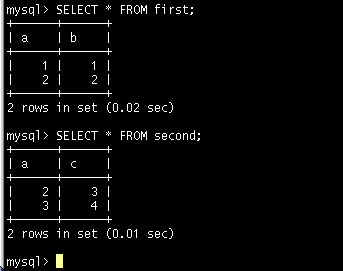
이제 두 테이블을 OUTER 조인으로 맺어보도록 하자.
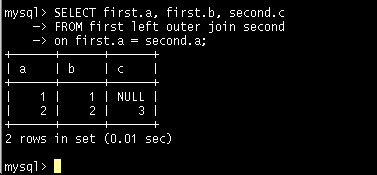
앞의 예는 first 테이블을 기준으로 하는 LEFT OUTER JOIN을 맺는 예이다.
위의 예에서 볼 수 있는 것과 같이 first 테이블에 있는 행은 모두 나왔다. 하지만 second 테이블의 컬럼 a는 1 값을 가지고 있지 않기 때문에 'NULL'로 표시하게 된다.
RIGHT OUTER JOIN도 LEFT OUTER JOIN과 똑같다. 한 가지 주의할 점은 OUTER JOIN할 때에는 컬럼 선택을 정확히 해야 한다. 다음의 예를 보도록 하자.
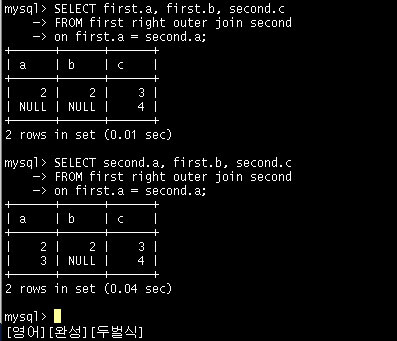
위 의 예는 굵은 글씨로 적혀진 부분을 제외하고는 같은 SQL 문이다. 그리고 앞의 LEFT JOIN을 RIGHT JOIN으로 바꾸었다. RIGHT JOIN의 경우 오른쪽에 있는 테이블이 기준 테이블이다. 따라서 second 테이블에 있는 행은 모두 나와야 한다.
우선 두 예에서 NULL 값이 리턴된 행에 주의를 기울여 보자. 첫 번째 SQL 문의 경우는 first.b에 대한 값은 처음부터 second 테이블에 없기 때문에 'NULL' 값이 나오는 것이 정상이다.
하지만 first.a 값이 왜 NULL이 나왔는지 의아해 할 수도 있으나 조금만 생각해보면 이 역시 당연한 결과이다. 이 SQL 문에서 주가되는 테이블은 어디까지나 second 테이블이다.
두 번째 SQL 문과 같이 second 테이블에서 a 컬럼의 값은 2와 3이 나와야 하지만 first 테이블에서 a 컬럼의 값이 3인 행은 없기 때문에 'NULL' 값이 출력된 것이다.
[셀프 조인(SELF JOIN)]
음식점이 '셀프'인 곳을 가면 음식을 자기 자신이 날라야 한다. SELF JOIN은 일반적인 조인과 똑 같은 역할을 하지만 조인할 테이블이 다른 테이블이 아니라 자기 자신이라는 점에서만 다르다.
앞에서 만든 second 테이블에서 컬럼 a와 컬럼 c를 조인해 보도록 하자.
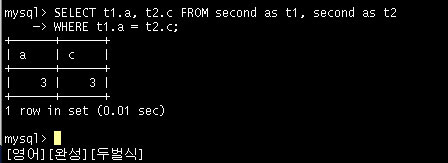
A 컬럼과 c 컬럼의 값이 같은 행은 하나의 행밖에 없다.
SELF JOIN의 경우 어려운 것은 없다.
하 지만 SELF JOIN을 어디에 사용할 수 있는가가 대단히 중요하다. SELF JOIN은 조직도와 같이 어떤 계층 구조를 나타내는데 사용할 수 있다. 한 테이블에 조직명과 해당 조직의 상위 조직 컬럼이 있다고 한다면 SELF JOIN을 사용해서 조직의 계층 구조를 만들어 낼 수 있다.
[유니온(UNION)]
UNION은 JOIN의 한 방법이 아니지만 JOIN과 같이 공부하면 더욱 이해하기 쉽기 때문에 JOIN에 대해서 공부한 김에 UNION에 대해서도 짚고 넘어가도록 하자.
JOIN 이 두 개 테이블의 공통된 요소에 초점을 맞춘다면 UNION의 두 개의 다른 SQL 문의 결과를 합하는 역할을 한다. 수학 개념을 빌려서 이야기한다면 JOIN은 교집합에 초점을 맞추는 것이고(물론 교집합의 개념과 정확히 일치하지는 않는다.), UNION은 합집합과 유사한 개념이다. 이전에 JOIN을 공부하면서 만든 테이블을 가지고 UNION에 대해서 실습해 보도록 하자. 그리 어려운 개념이 아니기 때문에 예제를 보면 이해할 수 있을 것이다.
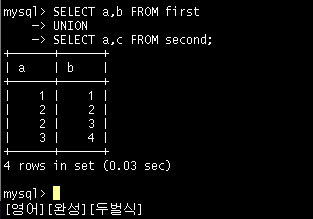
MySQL은 UNION을 만나면 두 개의 SQL을 하나인 것처럼 만들어서 돌려준다.
===========================================================================
[NOTE]
[MySQL 4.1에서 지원할 SUBQUERY]
앞으로 발표될 MySQL 4.1 버전은 개발자나 시스템 운영자에게 모두 설레는 버전이 될 것임에 틀림이 없다. 지원 예정 기능 중에 가장 기대되는 기능 중에 하나가 바로 서브쿼리이다.
프로그램을 짜본 사람이라면 함수를 만들어 보았을 것이다. 함수는 어떤 매개 변수를 넘겨주면 적절한 처리를 한 다음에 특정 리턴 값을 함수를 부른쪽에 넘겨준다.
서브쿼리도 일종의 함수와 비슷하지만 특정 값 대신에 SQL을 처리하고 난 후의 결과 값을 원래 SQL 문에 넘겨준다. 차후 MySQL이 업그레이드된다면 반드시 깊이 있게 공부해야할 내용이다.
===================================================================================
[집합함수(Aggregate Function)와 GROUP BY]
엑셀과 같은 프로그램을 사용하면 자주 사용하는 함수가 있다.
합을 구하고 건수가 몇 건이고 평균이 몇이고 또는 최대값, 최소값과 같은 것을 구해야 하는 경우가 있다. 거의 모든 데이터베이스에는 이런 기본적인 기능을 제공하고 있다.
상용 데이터베이스의 경우는 회계 및 수학에 관련된 복잡한 함수까지 제공하기도 한다. 그러나 일반적으로 데이터베이스를 사용하는 사람이라면 위에서 말한 기본적인 함수만으로도 충분한 결과를 얻을 수 있다.
이제 각 집합 함수와 GROUP BY 구문에 대해서 알아보도록 하자. 공부하기 앞서, 집합 함수를 사용하기 위한 샘플 테이블을 만들고 샘플 데이터도 넣어보도록 하자.
일단 payment 테이블이 있다면 테이블을 삭제한다.
그리고 새로인 테이블을 하나 만들어 보도록 하자.
샘플 데이터를 payment 테이블에 넣어보도록 하자.
==============================================================================================다음에는 group by, count 함수, sum 함수 등등에 대해서 올릴 것입니다...
===============================================================================
[출처] MYSQL 테이블간의 관계, 조인(JOIN) - 09 (DataBase Diary) |작성자 흥돌이
'DBMS' 카테고리의 다른 글
| SQL요약. (0) | 2010.05.11 |
|---|---|
| having 절의 사용은 언제? (0) | 2008.04.14 |
| MySQL에서 greatest와 least를 이용하여 ranking 구하기... (0) | 2008.02.19 |
| MySQL 실행계획, Explain 정보보는법 (0) | 2008.02.10 |
| 랜덤키 생성을 좀더 그럴듯하게 보이기.... (0) | 2008.01.29 |
- Filed under : DBMS
